Architecture#
Let us now consider the roles of the different Remote Services components. Consider a Remote Services deployment:
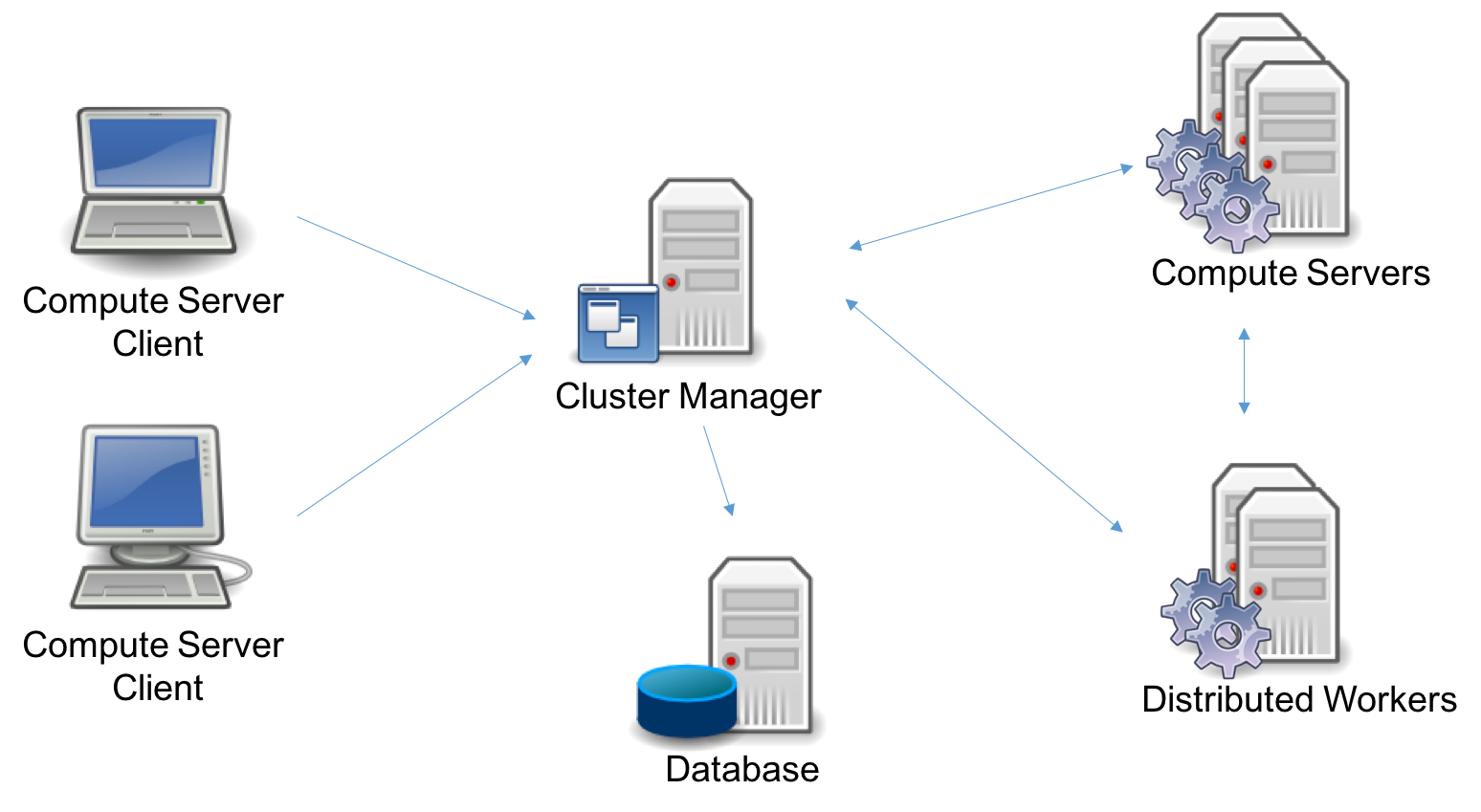
The deployment may consist of five distinct components: the Clients, the Cluster Manager, the Database, the Compute Server nodes, and the Distributed Worker nodes. Several of these are optional, and a few can be replicated for high availability. This gives a variety of topology options, which we’ll discuss shortly. First, let us consider the components individually.
Cluster Manager#
The Cluster Manager is the central component of the architecture. It provides the following functions:
Security. The Cluster Manager is in charge of authenticating and authorizing all access to the cluster. It does this by managing user accounts and API keys, and by controlling access to all Remote Services nodes (Compute Servers or Distributed Workers).
Cluster Monitoring. The Cluster Manager gives visibility to all operations on the cluster: available nodes, licenses, and jobs. It also records and retains job history, including detailed metadata and engine logs.
Batch Management. The Cluster Manager controls the batch creation process and the storage of input models and output solutions. It also keeps a history of batches. Internally, it communicates with the nodes to submit and monitor batch jobs.
REST API. All of the functions provided by the Cluster Manager are exposed in a REST API. This REST API is used by all built-in clients:
gurobi_cl,grbtune,grbcluster, and the Web User Interface. The REST API can also be used by user programs.Web User Interface. The Cluster Manager includes a Web Application Server that provides a complete and secured Web User Interface to your Compute Server cluster.
The Cluster Manager is optional. You can build a self-managed Remote Services cluster, but it will be missing many features.
Cluster Manager installation is covered in this section.
Database#
The database supports the Cluster Manager. It stores a variety of information, including data with long lifespans, like user accounts, API keys, history information for jobs and batches, and data with shorter lifespans, like input models and their solutions for batch optimization.
How much space does this database require? This will depend primarily on the expected sizes of input and output data for batches. The Cluster Manager will capture and store the complete model at the time a batch is created, and it will store the solution once the model has been solved. These will be retained until they are discarded by the user, or until they expire (the retention policy can be configured by the Cluster Manager system administrator, in the settings section). The data is compressed, but it can still be quite large. To limit the total size of the database, we suggest that you discard batches when you are done with them. Note that discarding a batch doesn’t discard the associated (small) metadata; that is kept in the cluster history.
The Cluster Manager can be connected to three types of database servers:
MongoDB version 4.4 or later, deployed on-premise, on the Cloud, or hosted by a SaaS provider.
Amazon Web Services (AWS) DocumentDB 4.0 or 5.0, when deployed to AWS.
Azure CosmosDB 4.2, when deployed to Microsoft Azure.
Cluster Manager users must install and configure their own database as part of the Compute Server installation process. It can be deployed as a single node or as a cluster for high availability.
Compute Server Node#
A Compute Server node is where optimization jobs are executed. Each such node has a job limit that indicates how many jobs can be executed on that node simultaneously. The limit should reflect the capacity of the machine and typical job characteristics. Compute Server nodes support advanced capabilities such as job queueing and load-balancing. Deploying a Compute Server requires a Gurobi license.
Compute Server node installation is covered in this section.
Distributed Worker Node#
A Distributed Worker node can only be used as a worker in a distributed algorithm. Only one job can run on such a node at a time and it does not support queueing or load balancing. This type of node does not require a Gurobi License.
Distributed Worker installation is covered in this section.
Architecture Topologies#
Let us now review a few common deployment configurations.
Cluster Manager with a single node#
In this deployment, we only need to deploy one instance of a Cluster Manager with the Database and a single Compute Server node. This is appropriate for small environments so that you can offload simple optimization tasks to one Compute Server.
Cluster Manager with multiple nodes#
If you need to handle more jobs concurrently, you will need to add more Compute Server nodes. Also, if you want to run distributed algorithms, several Distributed Worker nodes will be needed. To this end, you can deploy one instance of the Cluster Manager (with a Database), and connect those nodes to the Cluster Manager.
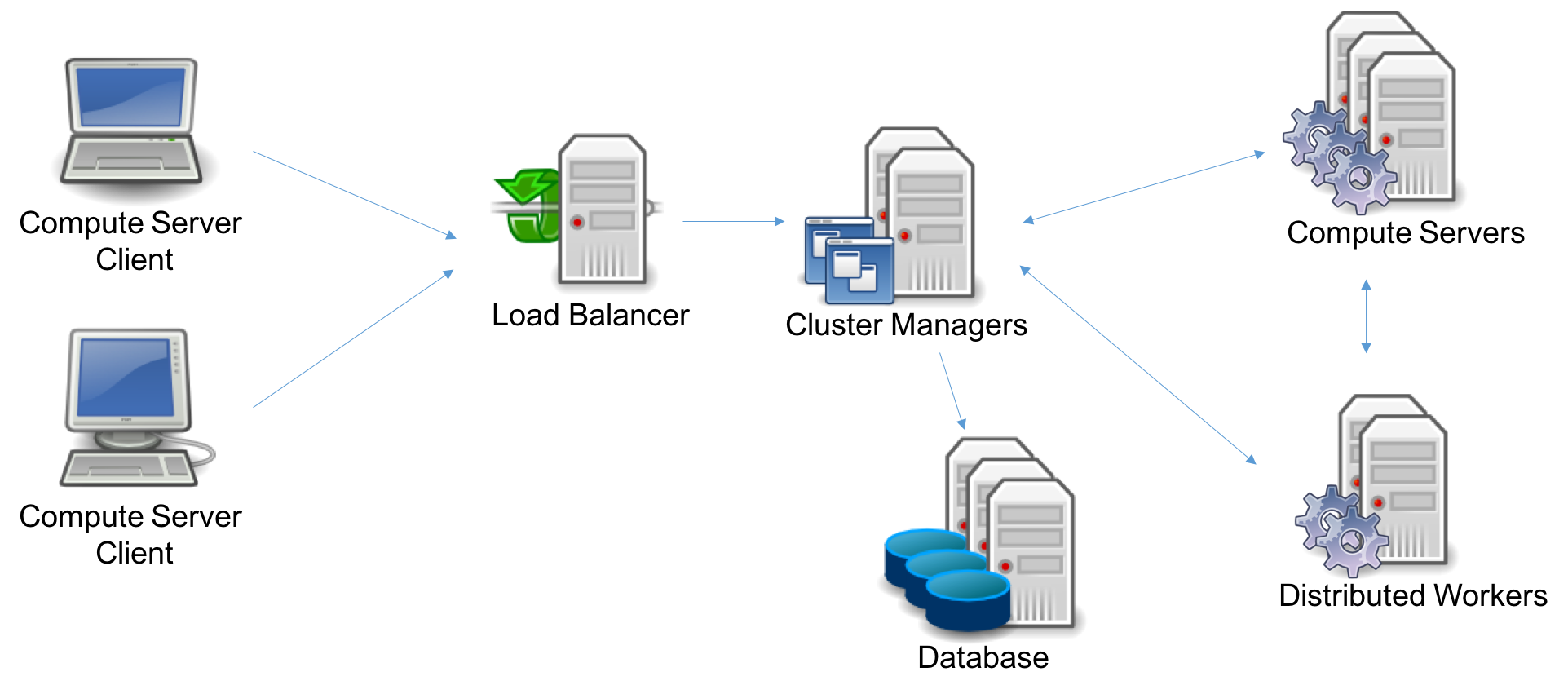
Scalable Cluster Manager#
If you have even more concurrent users, or if you need a scalable and
high available architecture, several instances of the Cluster Manager
can be started. In this case, you may need to install and set up a
regular HTTP load balancer (such as Nginx) in front of the Cluster
Manager instances. Cluster Manager server instances are stateless and
can be scaled up or down.
The database itself can be deployed in a cluster. In a MongoDB cluster, one of the nodes is chosen dynamically as the primary, while the others are deemed secondary. Secondary nodes replicate the data from the primary node. In the event of a failure of the primary node, the Cluster Manager will automatically reconnect to a new primary node and continue to operate.
In this deployment, several Compute Server nodes are also recommended. In the event of a node failure, any jobs currently running on the failed node will fail, but new jobs will continue to be processed on the remaining nodes.
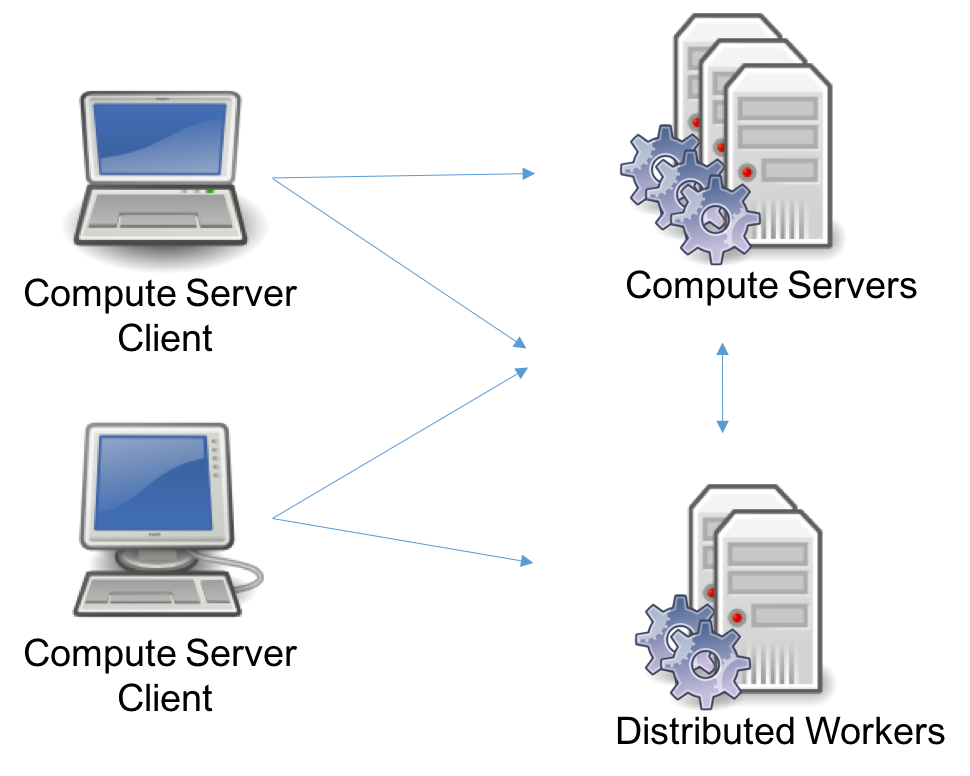
Self-Managed Cluster#
Finally, Compute Server nodes and Distributed Worker nodes can be deployed by themselves, without a Cluster Manager or a Database. This was actually the only option in Gurobi version 8 and earlier. In this configuration, you will not benefit from the latest features: secured access using user accounts and API keys, persistent job history, batch management, and the Web User Interface.