Distributed Algorithms#
Gurobi Remote Services allow you to perform distributed optimization. All you need is a cluster with more than one node. The nodes can be either Compute Server or Distributed Worker nodes. Ideally these nodes should all give very similar performance. Identical performance is best, especially for distributed tuning, but small variations in performance won’t hurt overall results too much.
Distributed Workers and the Distributed Manager#
Running distributed algorithms requires several machines. One acts as the manager, coordinating the activities of the set of machines, and the others act as workers, receiving tasks from the manager. The manager typically acts as a worker itself, although not always. More machines generally produce better performance, although the marginal benefit of an additional machine typically falls off as you add more.
As we mentioned earlier, Distributed Workers do
not require Gurobi licenses. You can add any machine to a Remote
Services cluster to act as a Distributed Worker. The manager does
require a distributed algorithm license (you’ll see a DISTRIBUTED=
line in your license file if distributed algorithms are enabled).
A typical distributed optimization will look like the following, with all machines belonging to the same Remote Services cluster:
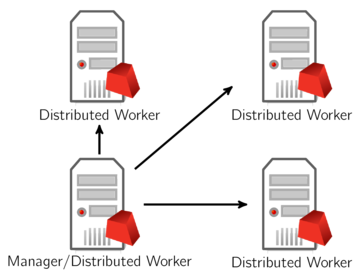
The workload associated with managing distributed algorithms is quite light, so a machine can handle both the manager and worker roles without degrading performance.
Another option is to use a machine outside of your Remote Services cluster as the manager:
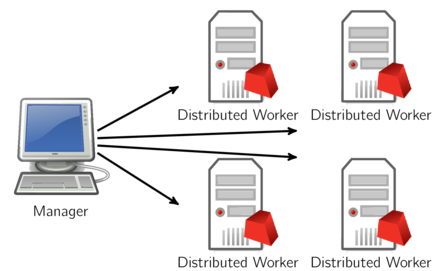
Note that we only allow a machine to act as manager for a single distributed job. If you want to run multiple distributed jobs simultaneously, you’ll need multiple manager machines.
Configuration#
Before launching a distributed optimization job, you should run the
grbcluster nodes command to make sure the cluster contains more than
one live machine:
> grbcluster nodes
If you see multiple live nodes, then that cluster is good to go:
ID ADDRESS STATUS TYPE LICENSE PROCESSING #Q #R JL IDLE %MEM %CPU
b7d037db server1:61000 ALIVE COMPUTE VALID ACCEPTING 0 0 2 1m 3.00 2.23
eb07fe16 server2:61001 ALIVE WORKER N/A ACCEPTING 0 0 1 1m 2.95 5.33
We should reiterate a point that was raised earlier: you do not need a Gurobi license to run Gurobi Remote Services on a machine. While some services are only available with a license, any machine that is running Gurobi Remote Services will provide the Distributed Worker service.
Running a distributed algorithm is simply a matter of setting the
appropriate Gurobi parameter. Gurobi supports distributed MIP,
concurrent LP and MIP, and distributed tuning. These are controlled with
three parameters: DistributedMIPJobs, ConcurrentJobs, and
TuneJobs, respectively. These parameters indicate how many distinct
Distributed Worker jobs you would like to start. Keep in mind that the
initial Compute Server job will act as the first worker.
Note that jobs are allocated on a first-come, first-served basis, so if multiple users are sharing a cluster, you should be prepared for the possibility that some or all of your nodes may be busy when you request them. Your program will grab as many as it can, up to the requested count. If none are available, it will return an error.
Running a Distributed Algorithm as an Interactive Job#
To give an example, if you have a cluster consisting of two machines
(server1 and server2), and if you set TuneJobs to 2 in
grbtune …
> grbtune TuneJobs=2 misc07.mps
…you should see output that looks like the following:
Capacity available on 'server1:61000' - connecting...
...
Using Compute Server as first worker
Started distributed worker on server2:61000
Distributed tuning: launched 2 distributed worker jobs
This output indicates that two worker jobs have been launched, one on
machine server1 and the other on machine server2. These two jobs
will continue to run until your tuning run completes.
Similarly, if you launch distributed MIP …
> gurobi_cl DistributedMIPJobs=2 misc07.mps
…you should see the following output in the log:
Using Compute Server as first worker
Started distributed worker on server2:61000
Distributed MIP job count: 2
Submitting a Distributed Algorithm as a Batch#
With a Cluster Manager, you can also submit your distributed MIP and
concurrent MIP as a batch using the batch solve command. Distributed
tuning is not yet supported. Here is an example:
./grbcluster batch solve DistributedMIPJobs=2 misc07.mps
info : Batch f1026bf5-d5cf-44c9-81f8-0f73764f674a created
info : Uploading misc07.mps...
info : Batch f1026bf5-d5cf-44c9-81f8-0f73764f674a submitted with job d71f3ceb...
As we can see, the model was uploaded and the batch was submitted. This
creates a parent job as a proxy for the client. This job will in turn
start two worker jobs because we set DistributedMIPJobs=2. This can
be observed in the job history:
> grbcluster job history --length=3
JOBID BATCHID ADDRESS STATUS STIME USER OPT API PARENT
d71f3ceb f1026bf5 server1:61000 COMPLETED 2019-09-23 14:17:57 jones OPTIMAL grbcluster
6212ed73 server1:61000 COMPLETED 2019-09-23 14:17:57 jones OPTIMAL d71f3ceb
63cfa00d server2:61000 COMPLETED 2019-09-23 14:17:57 jones OPTIMAL d71f3ceb
Using a Separate Distributed Manager#
While Distributed Workers always need to be part of a Remote Services
cluster, note that the distributed manager itself does not. Any machine
that is licensed to run distributed algorithms can act as the
distributed manager. You simply need to set WorkerPool and
WorkerPassword parameters to point to the Remote Services cluster
that contains your distributed workers. Note that the Cluster Manager
can not act as the distributed manager.
To give an example:
> gurobi_cl WorkerPool=server1:61000 WorkerPassword=passwd DistributedMIPJobs=2 misc07.mps
You should see the following output in the log:
Started distributed worker on server1:61000
Started distributed worker on server2:61000
Distributed MIP job count: 2
In this case, the distributed computation is managed by the machine where you launched this command, and the two distributed workers come from your Remote Services cluster.